Lokaler PDF Chat - KI-basierte Dokumentenanalyse
Ein persönliches Projekt zur Entwicklung eines lokalen PDF Chat Tools, das mir bei der Analyse wissenschaftlicher Arbeiten hilft.
Vorstellung des Projektes
Im Rahmen meiner Masterarbeit verbringe ich derzeit viel Zeit mit dem Lesen von wissenschaftlichen Arbeiten. Ein Prozess der mir zum einen zwar viel Spaß macht, aber der teilweise auch sehr mühselig sein kann, besonders wenn man mit den Thematiken der Arbeiten nicht vertraut ist.
Um diesen Prozess zu erleichtern verwende ich natürlich auch komerziell verfügbare Tools wie Consensus um wissenschaftliche Arbeiten zu finden und eine Zusammenfassung zu erhalten, aber auch andere Tools wie ChatGPT um mir bestimmte Punkte erklären zu lassen oder einen ersten Entwurf für einen Paragraphen zu generieren. Hierbei kommt es leider oft dazu, dass diese Modelle hallucinieren und die Informationen entweder verdrehen, neue Informationen einfügen oder einfach inkorrekte Fakten generieren.
Als Experiment und persönliches Lernprojekt kam mir die Idee, ein eigenes Tool zu entwickeln. Ziel war es, ein lokales System zu erstellen, das wissenschaftliche Arbeiten mit Hilfe von KI analysiert und einen PDF Chat bereitstellt, der Informationen ausschließlich basierend auf dem tatsächlichen Inhalt des Dokumentes beantwortet. Das Projekt dient hauptsächlich als Proof-of-Concept und hilft mir, die Möglichkeiten und Grenzen lokaler KI-Systeme besser zu verstehen.
Demonstration des PDF Chat Tools in Aktion
Wie funktioniert es unter der Haube?
Frontend
Im Frontend habe ich mich für eine einfache Angular Anwendung entschieden, die es ermöglicht ein PDF Dokument hochzuladen und dieses anschließend zu analysieren und gleichzeitig lesen zu können.
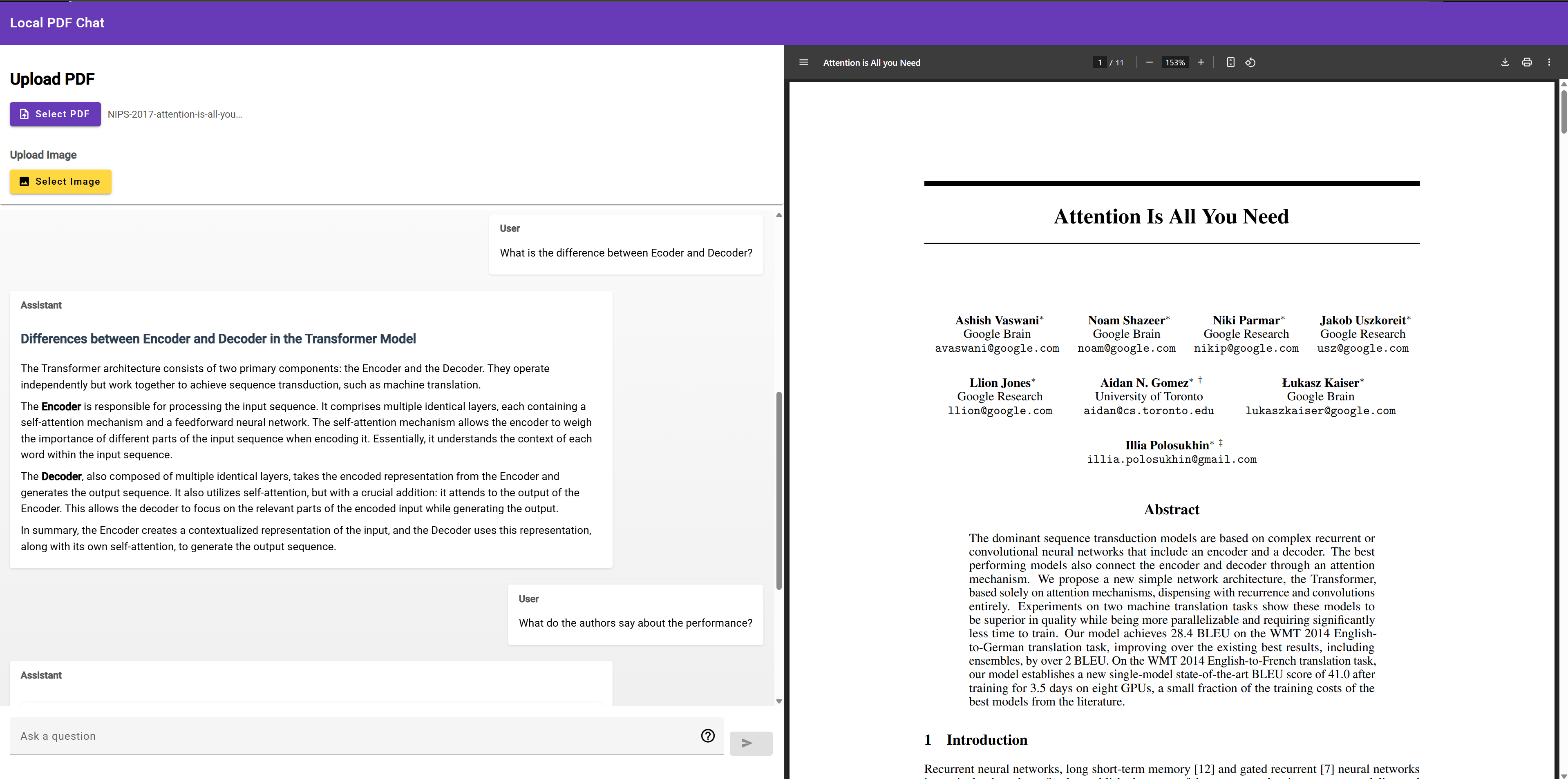
PDF Chat Frontend - Übersicht der Angular-Anwendung
Aufgrund der länger dauernden Analysezeiten habe ich einige Statuselemente eingebaut, welche den User darüber informieren, was gerade passiert und wie weit dieser Prozess fortgeschritten ist.
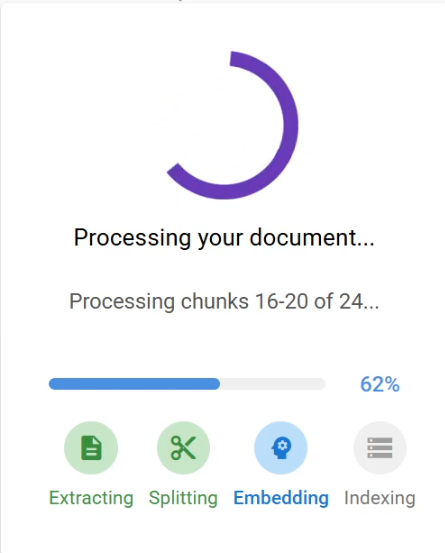
Status-Anzeige während der Dokumentenanalyse
Backend
Das Backend bildet das Herzstück meines Tools und nutzt folgende Technologien:
- Python/Flask: Als Basis für das Web-Backend, das die Anfragen und PDF-Uploads verwaltet.
- FAISS: Ein extrem schneller Vector-Store für die semantische Suche.
- PyMuPDF: Für die Text- und Tabellenerkennung in PDF-Dokumenten.
- Ollama: Zur Erstellung der Embeddings und für die eigentliche KI-Chat-Funktionalität.
Besonders bei der Analyse und der Beantwortung der Fragen kann viel Information an den Nutzer weitergegeben werden. Die eingegebene Frage wird in 5 abgewandelte Fragen umgewandelt und anschließend mit diesen 5 Fragen der PDF Dokument durchsucht. Diese Fragen werden dann an den User weitergegeben und es wird eine Antwort generiert, welche alle 5 Fragen beantwortet.
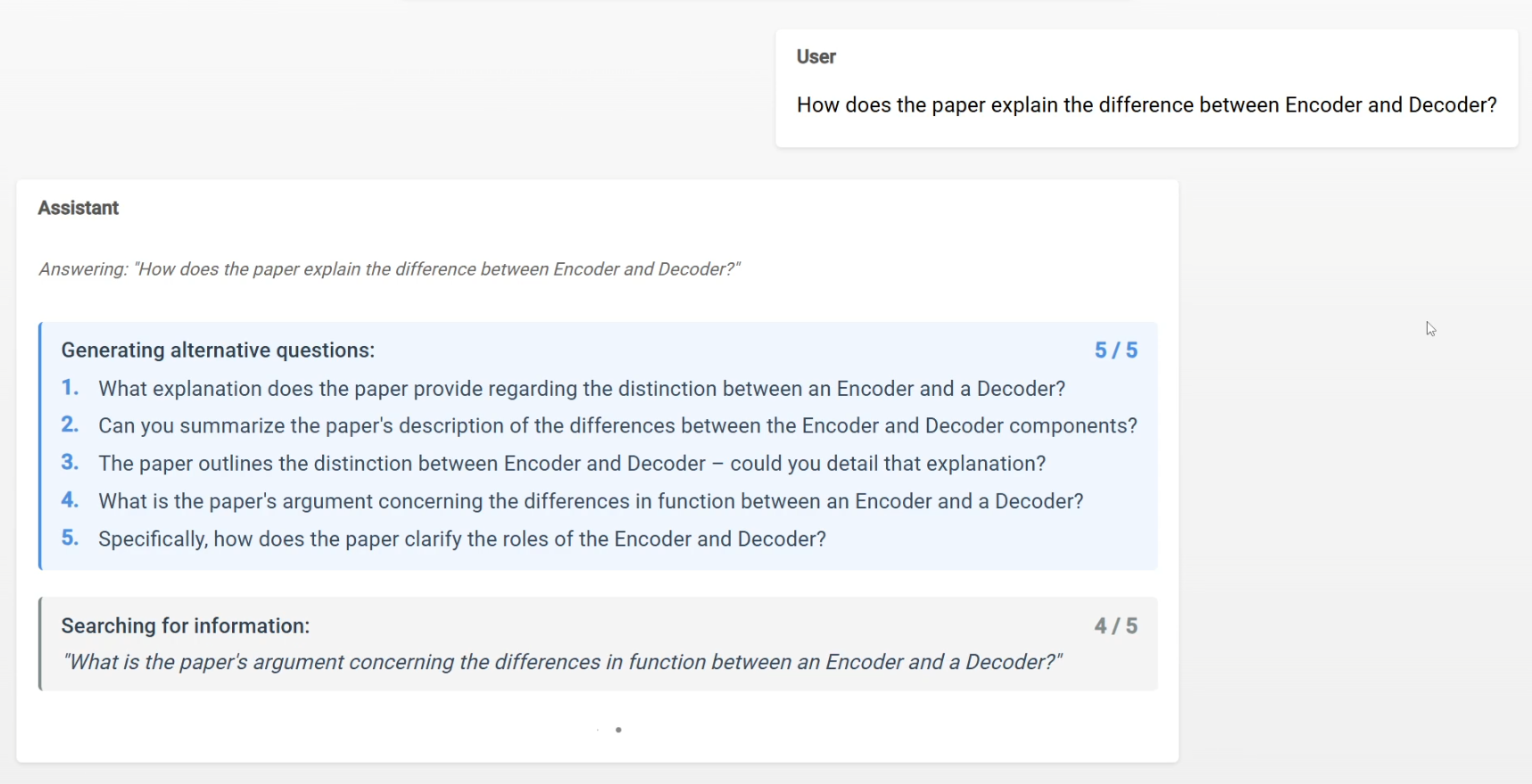
Frage-Analyse und Antwortgenerierung
Aktuelle Einschränkungen
Wie bei jedem Proof-of-Concept gibt es auch bei PDF Chat einige Einschränkungen:
- Die Analysezeit ist noch relativ lang, besonders da ich aktuell nur auf meine RTX 4070 GPU zurückgreife
- Die Verarbeitung von Tabellen und Bildern funktioniert zwar, aber teilweise werden die Informationen nicht korrekt erkannt und es kommt zu Fehlern in der Antwort
- Die aktuelle Implementierung erlaubt es nur einen PDF Dokument hochzuladen und dieses anschließend zu analysieren. Es ist also noch nicht möglich mehrere Dokumente zu vergleichen oder Informationen aus verschiedenen Quellen zu verknüpfen.
Code öffentlich zugänglich
Der Code ist auf Github zu finden und kann frei verwendet und angepasst werden.